A comparison on SQL Server data access methods
Type providers + Query Expressions
F# Query Expressions (aka LINQ 2.0) is lovely and useful technology. It makes writing data access code a pleasant exercise. There are several different implementations available: SQLProvider (recent community effort), SqlDataConnection/DbmlFile and SqlEntityConnection/EdmxFile.
But I would like to point out some reasons you might prefer SqlCommandProvider over those. Take a look at this StackOverflow issue. There are dozens of similar questions (hundreds if you include C# LINQ which is essentially the same issue).
So, what's a deal? The thing is, you can have perfectly valid F# code that compiles but still fails at run-time because of unsupported F#-to-SQL translation semantics. Contrary, SqlCommandProvider offers "What You See Is What You Get" approach. Once F# code involving SqlCommandProvider passes compilation stage you are guaranteed to have valid executable (both F# code and T-SQL).
Lack of control and opaqueness of F#-to-SQL conversion spells performance problems too. At times developers are really frustrated by ineffective T-SQL code generated by type providers (most of EF users are aware of this issue). Evolution and changes in T-SQL code generated by type provider may present certain problems too. A data access code that is performing well today can become suboptimal tomorrow. SqlCommandProvider gives you direct access to full power of T-SQL scripting including the latest features which are often unavailable in type providers because they target older or different versions of the system.
Common for all TypeProviders
- You write logic, not POCO-objects and mappings
- If your database changes, your code breaks at compile time
- No SQL-injection vulnerabilities
- Commit to existing transactions so you can mix with other technologies
- You can call stored procedures if needed
- Joins and nested in-queries are supported so you can avoid "n+1 database hits" problems
FSharp.Data.SqlClient
Good:
- Supports .NET Standard and .NET Core
- User has full control of SQL
- Which allows full utilization of database indexes with complex queries
- SQL syntax is already familiar for many
- Exposes database objects directly in code
- Supports async database operations
- Used in production for enterprise development for years
- Open source
Not so good:
- By default supports only Microsoft SQLServer and T-SQL
- Code overhead if you have a large amount of different small operations
- Doesn't generate domain model for work with C#
SQLProvider
Good:
- Supports .NET Standard and .NET Core
- Supports any database (MSSQL, MySQL, PostgreSQL, Oracle, Odbc, ...)
- Changing the database is not actually huge work
- Makes effective simple SQL
- Supports async database operations
- Used in production for enterprise development for years
- Simplifies user code
- Open source
Not so good:
- No Manual control over generated SQL
- FSharp/LINQ query-syntax is a learning curve
- Doesn't generate domain model for work with C#
- Most LINQ-operations supported, but not yet complex group-by scenarios
- Updates in complex scenarios can be a pain
SqlDataConnection
Good:
- You can use generated DB-model from C#-projects
- Supports even complex LINQ-operations
- Used in production for enterprise development for years
Not so good:
- Generates EF-models in background
- Not dynamic
- Doesn't scale to large databases
- FSharp/LINQ query-syntax is a learning curve
- Closed source
- Supports only Microsoft SQLServer
- No support for .NET Standard / .NET Core
Rezoom.SQL
Good:
- User has full control of SQL
- Which allows full utilization of database indexes with complex queries
- SQL syntax is already familiar for many
- Supports SQLite, SQL Server, and PostgreSQL
- Open source
Not so good:
- No support for .NET Standard / .NET Core
- No support for MySQL, Oracle, ...
- Code overhead if you have a large amount of different small operations
- Doesn't generate domain model for work with C#
Dapper
FSharp.Data.SqlClient is much closer to the family of micro-ORMs rather than complete solutions like EntityFramework and NHibernate, hence comparison with the best of the breed - Dapper.
Dapper is a micro-ORM by StackOverflow with a main goal of being extremely fast. Here is a description from StackOverflow itself:
dapper is a micro-ORM, offering core parameterization and materialization services, but (by design) not the full breadth of services that you might expect in a full ORM such as LINQ-to-SQL or Entity Framework. Instead, it focuses on making the materialization as fast as possible, with no overheads from things like identity managers - just "run this query and give me the (typed) data".
Let's start with performance to get it out of the way.
Dapper comes with an excellent benchmark. The focus of the test is on deserialization. Here is how FSHarp.Data.SqlClient compares with all major .Net ORMs:
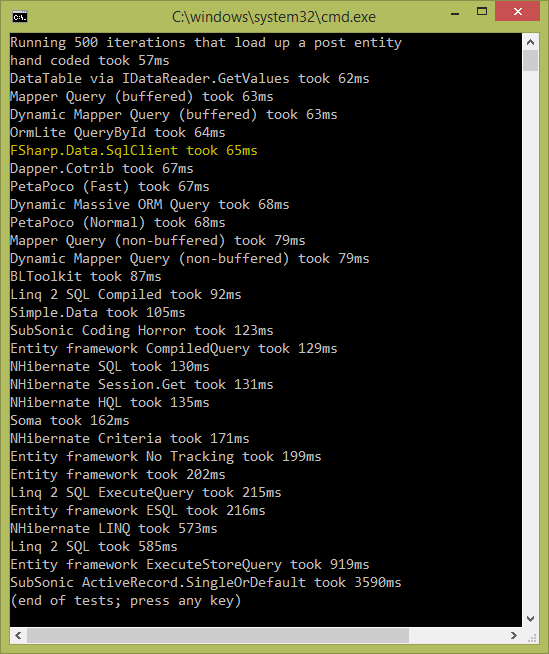
Tests were executed against SqlExpress 2012 so the numbers are a bit higher than what you can see on Dapper page. A test retrieves single record with 13 properties by random id 500 times and deserializes it. Runs for different ORMs are mixed up randomly. All executions are synchronous.
Note that we didn't put any specific effort into improving FSharp.Data.SqlClient performance for this test. The very nature of type providers helps to produce the simplest run-time implementation and hence be as close as possible to hand-coded ADO.NET code.
Now, to the usage. Line-by-line comparison is probably unfair as I'll end up comparing C# with F#, and C# is going to lose. Keeping in mind that FSharp.Data.SqlClient is not strictly an ORM in commonly understood sense of the term, here are the some pros and cons:
- Because result types are auto-generated, FSharp.Data.SqlClient doesn't support so-called multi-mapping
- As FSharp.Data.SqlClient is based on features specific for Sql Server 2012; Dapper provides better range of supported scenarios, including Mono
- Other side of this is that FSharp.Data.SqlClient fully supports SqlServer-specific types like hierarchyId and spatial types, which Dapper does not
- FSharp.Data.SqlClient fully supports User-Defined Table Types for input parameters with no additional coding required, as opposed to Dapper
- Dapper intentionally has no support for
SqlConnectionmanagement; FSharp.Data.SqlClient encapsulatesSqlConnectionlife-cycle including asynchronous scenarios while optionally accepting externalSqlTransaction.
Following FSharp.Data.SqlClient features are unique:
- Reasonable auto-generated result type definition so there is no need to define it in code
- This type also comes with
IDictionary<string,obj>andDynamicObjectimplementation - Sql command is just a string for other ORMs, while FSHarp.Data.SqlClient verifies it and figures out input parameters and output types so design-time experience is simply unparalleled
- Design-time verification means less run-time tests, less yak shaving synchronizing database schema with code definitions, and earliest possible identification of bugs and mismatches
SqlProgrammabilityProviderlets user to explore stored procedures and user-defined functions right from the code with IntelliSense
It is my believe that FSharp.Data.SqlClient comes closest to the mission of micro-ORM - to make conversion between data stored in database and .Net run-time types as painless as possible while keeping away from object-relational impedance mismatch as described in famous blog The Vietnam of Computer Science by Ted Neward.
Generating strongly typed DataSets
Using strongly typed DataSets requires creation of XSD schema which then used to generate C# code. Dubious pleasure of hand-crafting XSD aside, this traditional technique suffers from the same limitation as Entity Framework and such when compared to FSharp.Data.SqlClient: no design-time interaction with model database - it is up to a user to keep definitions and database schema in sync.
At the same time, FSharp.Data.SqlClient supports strongly typed data table as one of the result types. No XSD required.
